Last updated on August 23rd, 2021 at 02:31 pm
This crawl is perfect for when you want to get response codes, meta data and other high level information for a typical website. Sometimes the most simple things do not seem as obvious as maybe they should.
Here are the configuration settings you need to run a quick crawl on a typical website for the purposes of gathering internal link page inventory.
Page Inventory Crawl Settings for Screamingfrog
- Reset to the default configuration
Go to menu: File > Configuration > Clear default Configuration
- Set to spider mode
Go to menu: Mode > Spider
- Open crawl configuration settings
Go to menu: Configuration > Spider
- Update crawl configuration settings
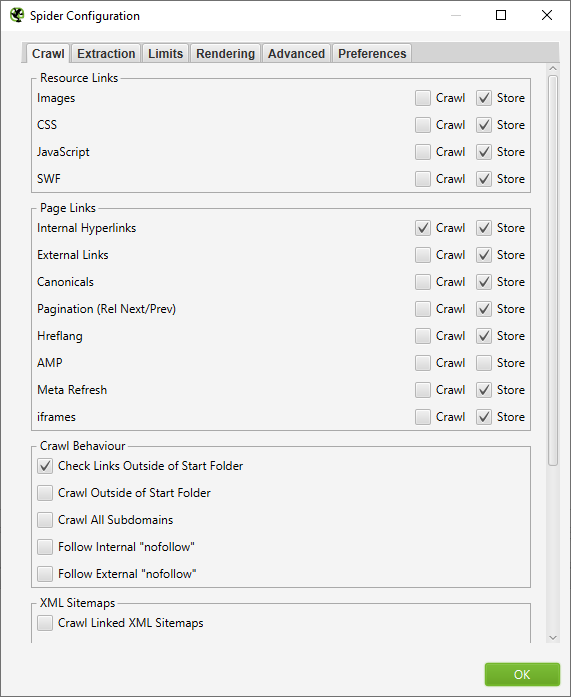
uncheck all of the crawl boxes in the “Resource Links” section then uncheck all of the crawl boxes except for “Internal Links” in the “Page links” section then click “OK”.
- Run the crawl
Put the domain root address in the address bar and click “Start” and watch the page data roll in.
If you are starting the crawl but you are not seeing the pages you expect to show up then the robots.txt may be disallowing sections of your site. If that is the case you can set the crawler to ignore the robots.txt in menu: configuration > robots.txt > settings and changing the drop down to “Ignore robots.txt” then try the crawl again.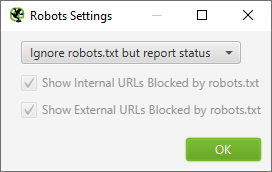
If robots.txt was not the issue, the website may be using JavaScript for navigation or hyperlinks. Try enabling JavaScript rendering in Menu: Configuration > Spider > Rendering tab. Change the dropdown to “JavaScript” then uncheck “Enable Rendered Page Screenshots” then click “OK”
enable javascript rendering in screamingfrog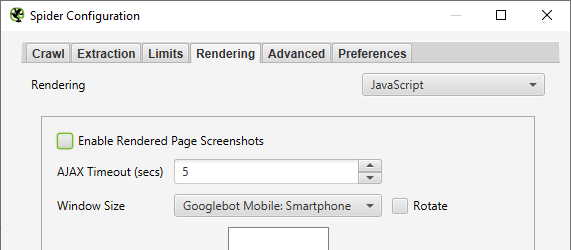
Screamingfrog YouTube channel
Screamingfrog User Guide
Screamingfrog Tutorials